After spending considerable amount of time in IT industry, one of the gentleman brought up this topic of bookish knowldge vs practical knowledge. Perception was that if you have not implemented certain pattern and you still know what the pattern does, then it is a bookish knowledge per the gentleman.
At an outset it might seem to be an agreeable statement, I have a different view. Most of the time architects evaulate the design in the mind’s labouratory. For example, a circuit breaker pattern. I dont think its a bookish knowledge if you know when to use a circuit breaker pattern. I do think it is a bookish knowledge if you just know how many states are there in the circuit breaker.
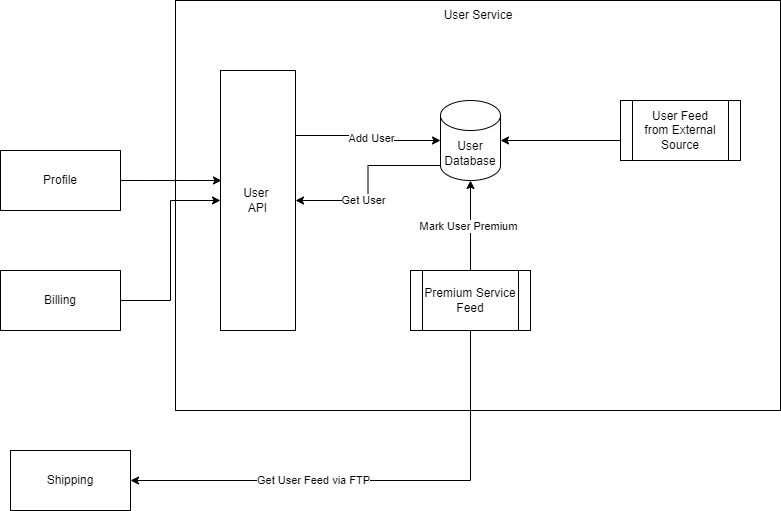
There is a tendency of loading up every pattern that is deemed best into the application. CQRS is a best example. These days I hear a lot about CQRS, and I know for sure that this is a pattern which suits complex systems where there are tones of business rules and behaviors in play. If you want to separate write and read databases, you can do it with read replicas. You don’t need CQRS for it.
Again, if you go behind business rules, not all business rules are complex even though they sometime look like. Storing and pulling customer data is not a business rule. Storing and pulling some entity is not at all a business rule. Business rule is something where you are going to calculate data based on rules, for example.. show the customers as premier if they have done purchase beyond certain limit.
Closing Note
This blog is a self reminder that there are different perspective to software architecture depending on the experiences one hold. I wrote this blog to dispel the notion that there is no wrong or right architecture. Architecture should ease out the pain for development team, devops, QA and deliver the right value to the organization. If there is no circuit breaker, CQRS and everyone is happy then that architecture is still good. If everyone is in pain fixing the code day in dayout because of wrong architecture with all the known best patterns, then why not simplify it.